
Amazon SageMaker with Amazon S3?
An important relationship enabling SageMaker's modularity.

My previous post tackled an important property of Amazon SageMaker. Turns out the platform is highly modular. You could use only a single SageMaker service, purely standalone. You can also simply swap the SageMaker service used in your project for something else if the need arises.

But what fuels that modularity?
The answer is actually fairly simple.
S3 is everywhere, SageMaker included
Amazon S3 is probably the most well known AWS service. The object storage (often confused with a file system!) lets you store arbitrary blobs of data in a key-value fashion.
There’s hardly any solution built in AWS that does not use S3 at some point. Ask any AWS user whether their system uses S3.
And so is SageMaker designed!
On a surface level SageMaker takes something out of S3, computes something and saves something back to S3:
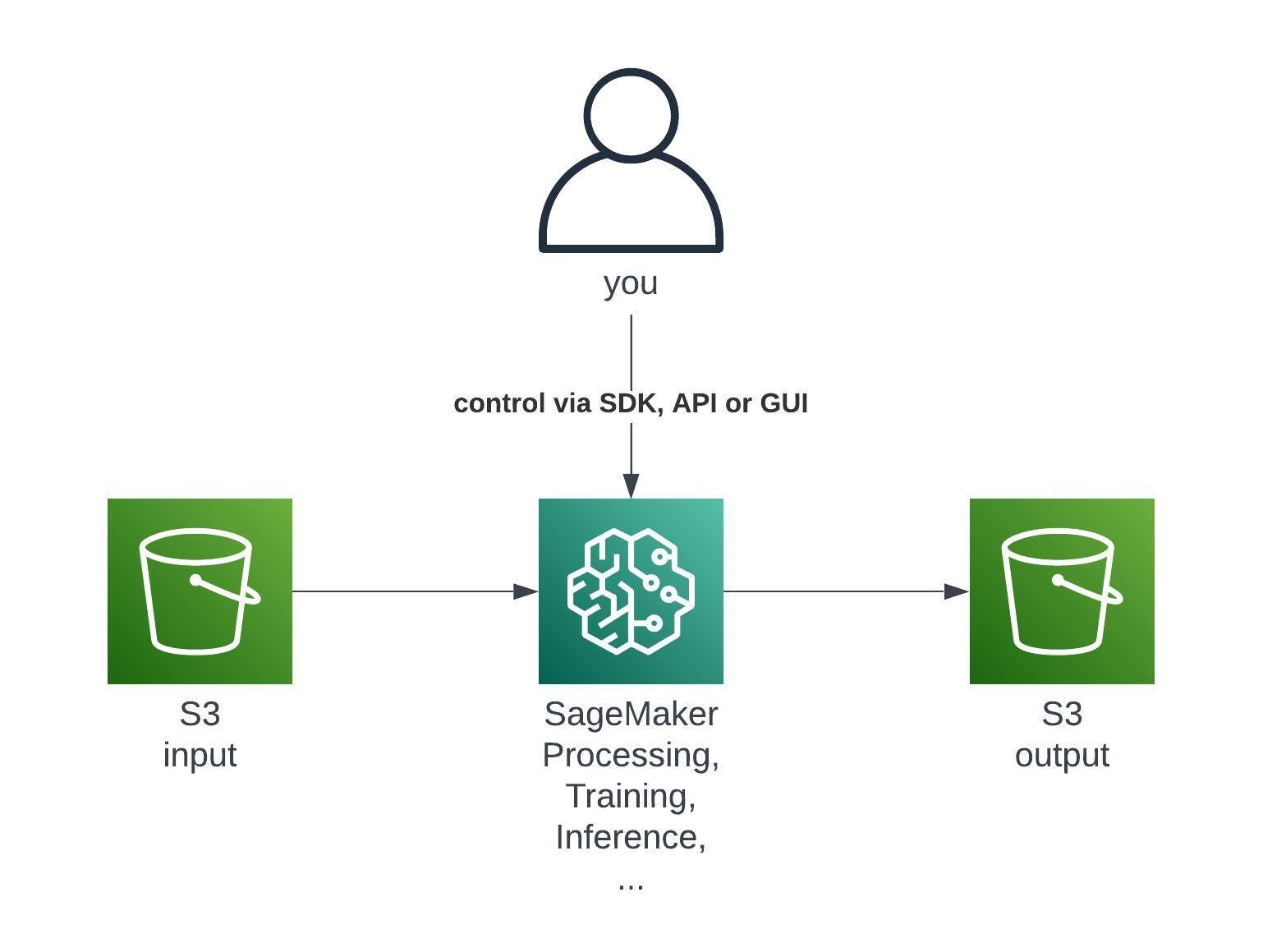
S3 holds the training data, the trained models, the debugging insights, inference inputs and outputs and more.
You can also leverage all the goodies from S3 itself such as Versioning, Lifecycle Policies, Event Notifications and more.
Forming a workflow
As you know, most data science projects naturally form a workflow. There are various tasks to be done in a specific order. You first process data, train an algorithm, store it in a model registry, then finally deploy and monitor it.
Mapping that onto SageMaker - you run SageMaker Processing, SageMaker Training, SageMaker Model Monitor, SageMaker Inference and several others.
Having in mind also the section above, if we were to draw a high level design of an arbitrary workflow, it would look as follows.
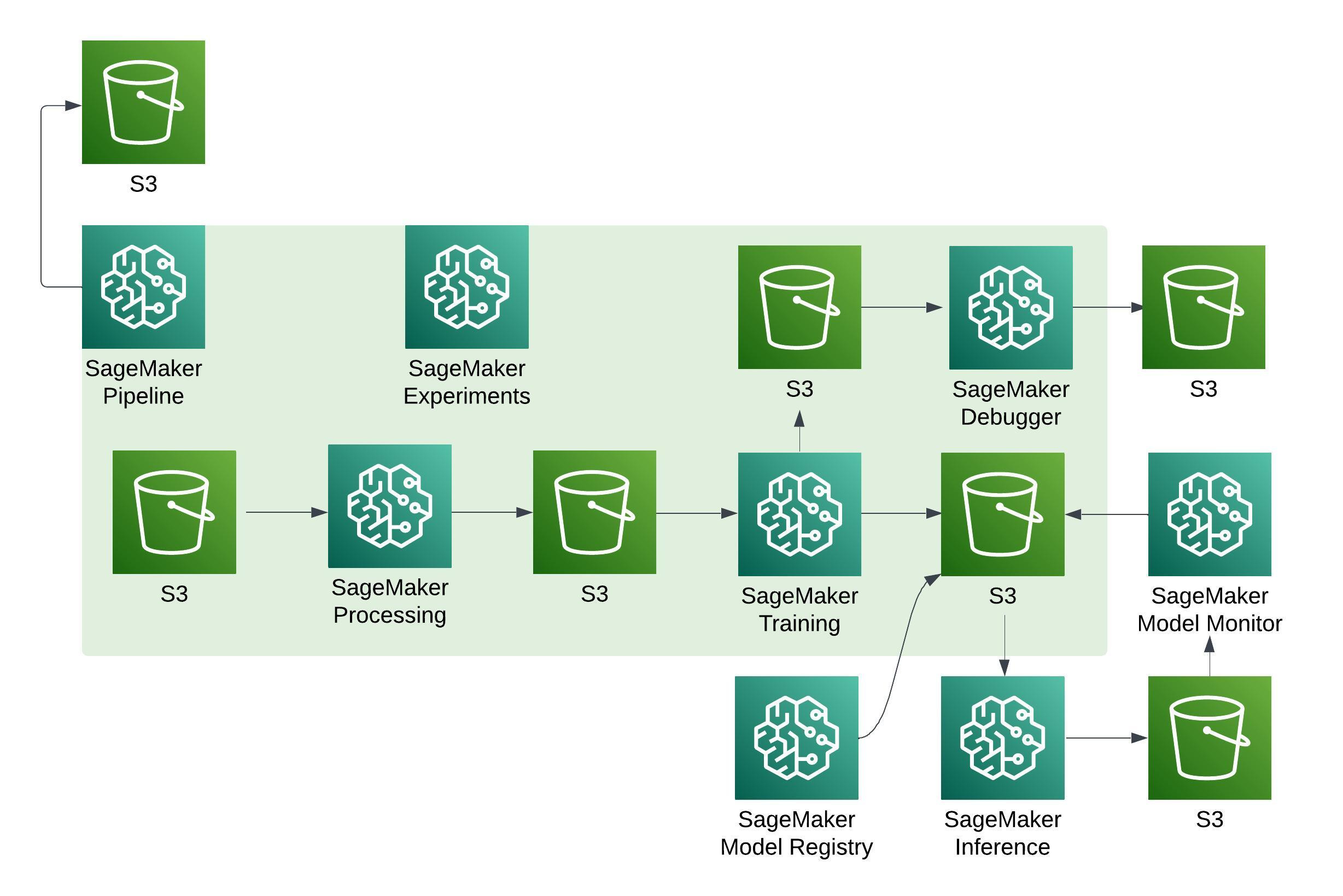
You immediately see that S3 becomes the interim place for storing arbitrary data between tasks.
One task’s output is another task’s input.
The modularity enabler
This fuels the modularity property. The pattern of taking something from S3 and saving it back, naturally forms a contract or an interface between tasks.
One task knows that its output should be stored in a specific way. Another task expects to load that specific thing.
If we maintain that contract, we’re free to swap underlying components!
And, since the S3 is a very widespread service, thousands technologies support reading from and saving to S3. This often makes the swap seamless.
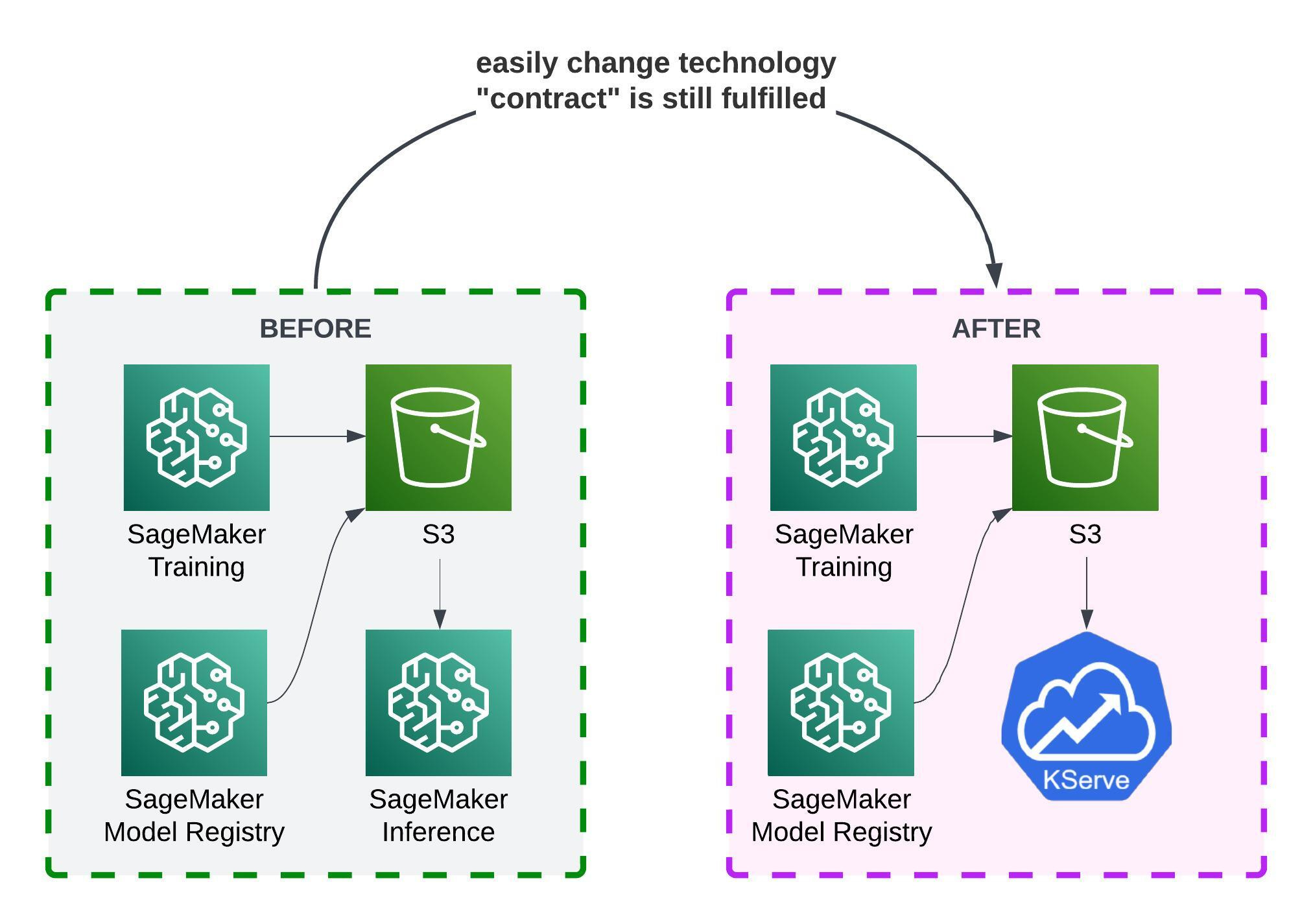
In this example KServe knows how to load models from S3 too. All your training pipeline stays the same. You only swapped a single component.
Conclusion
SageMaker heavily uses S3 as its place to store all the artifacts. Most SageMaker tasks expect to get their input from S3 and save their output to S3. This automatically forms a “contract” between these tasks and lets you swap SageMaker for other technologies if you wish.
Wait, are there any exceptions? What if I want to load data to SageMaker from elsewhere?
This will be tackled next.