
Use SageMaker Debugger to understand your training process inside out!

Model training can fail silently, without any explicit errors or stack traces. After many hours the training process finishes ...but the produced model is useless.
Amazon SageMaker Debugger is a handy way to mitigate this issue and get insights about your training process. Was the algorithm overfitting? Was the dataset imbalanced? Were there any IO bottlenecks? Was the GPU properly utilised? How much time was spent in a training loop?
Dozens of questions like these can be answered by using SageMaker Debugger.
How it works?
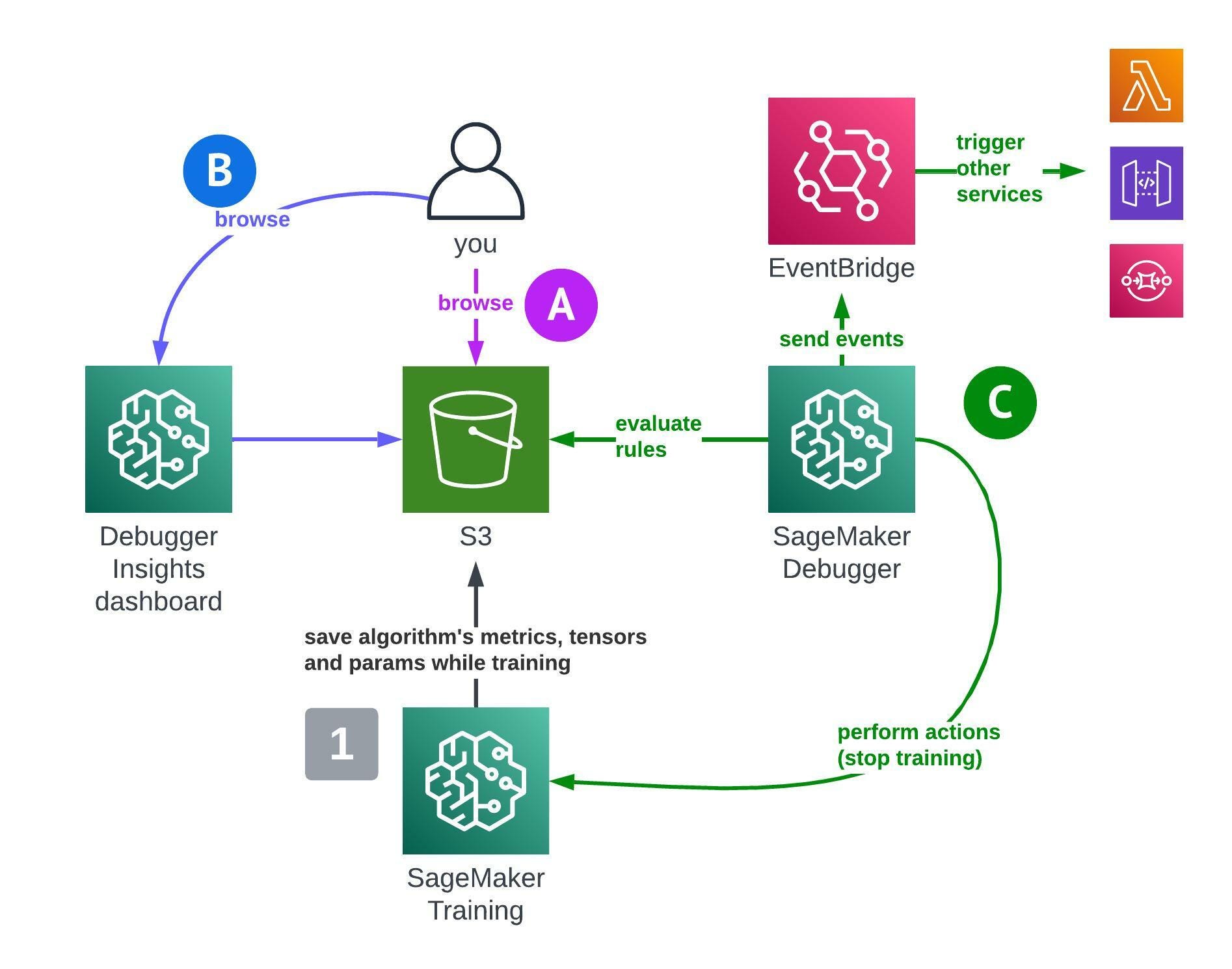
While configuring your SageMaker Training Job, you set up a debugger hook. This will automatically save metrics, tensors, and other parameters for every epoch as JSON files to S3. This is shown as 1️⃣ in the picture.
Adding that DebuggerHookConfig to a Training Job is straightforward:

Depending on the framework used (PyTorch, XGBoost, TensorFlow, your custom one) you specify collections of data points (such as tensors, metrics, feature importances etc.) in CollectionConfig.
These files can then be analysed after or during the training, by you or by SageMaker automatically. This boils down to three different scenarios (A, B, C).
Three ways to analyse your training process
Scenario A 💜 is the simplest one - you just query JSON data inside that S3 bucket yourself. You can draw various charts using your favourite tools such as seaborn or matplotlib and get your own insights from there. Manual work, but useful nevertheless.

Scenario B 💙 uses the AWS-provided dashboard with various ready-to-use charts. They show CPU, GPU, network usage and IO over time and can be useful to spot bottlenecks. Good addition, especially useful for multi node training.

Scenario C 💚 is the most powerful one. During training, SageMaker will analyse the training process for specified errors (called Rules).

If an issue is found, you see it in the Experiments UI and also get an EventBridge event. You can automatically shutdown the failing training job too!

There are many built-in rules to choose from, such as wrong initialisation, overfitting, vanishing gradients or class imbalance.

You can also create your own ones by implementing a Python class with your custom code. These analyses are run on separate machines as Processing Jobs and do not consume compute capacity from your Training Jobs.
This scenario is a great addition to your automated pipelines.
Summary
Using SageMaker Debugger helps mitigating the silent training errors. While prototyping, you can just browse the metrics and tensors yourself and also aid yourself with the provided SageMaker Debugger Insights Dashboards to spot all common issues. When you're closer to production phase, you start automating this behaviour using Rules and Actions.