
What does it mean to deploy a machine learning model?
...and what the hell is a machine learning model anyway? Machine learning models, inference servers and serving layers overview!

There are various machine learning algorithms available, designed to solve a specific task. You’ve heard about one of them a lot (neural network) a lot lately, due to models such as ChatGPT, DALL-E 2, GPT3 or BERT blowing up in popularity, but there are other algorithms too, such as gradient boosted trees or logistic regression.
What connects them is the fact that they’re trainable - they’re not of much use by themselves. Only after you teach them their task are they useful.
An overly-simplified training loop
The training loop looks as follows - you select an algorithm, prepare your dataset accordingly and then:
You feed an algorithm with a piece of data.
The algorithm examines the data and changes its underlying state ("internal parameters") to solve the task more efficiently.
That process is repeated until the algorithm's performance is no longer getting any better. Math&stats witchcraft is also involved!
What is a machine learning model?
Afterwards, what you usually do is save that trained algorithm. With a single line of code, model’s parameters are saved to a file on a disk (.pth, .pt, .pb, .json - depending on the ML framework used).
And voila - that file, along with some metadata, becomes your machine learning model! The model’s entire knowledge is contained in that file.
How does it look like internally? The actual contents of the file vary between used algorithm and framework, but it’s mostly floating point numbers. Lots of floating point numbers. Magic, huh?
There's still a problem though - what you ended up with was a file. How do you let others harness the power of your model?
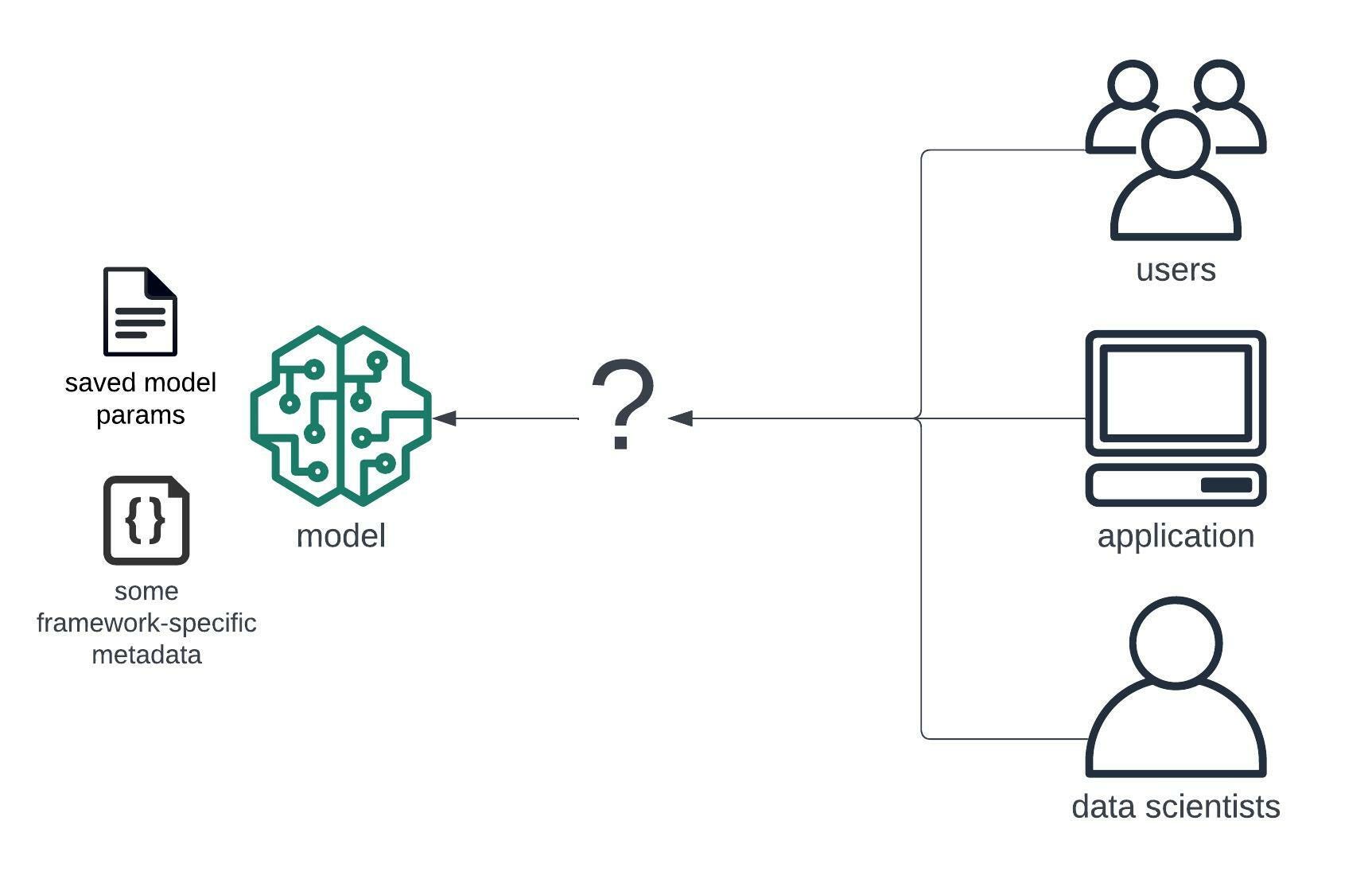
In some cases, like sharing for other data scientists, you could just upload the file somewhere and let others download it. They would just load that file into memory with a line of code and resume their work inside their data science environment.
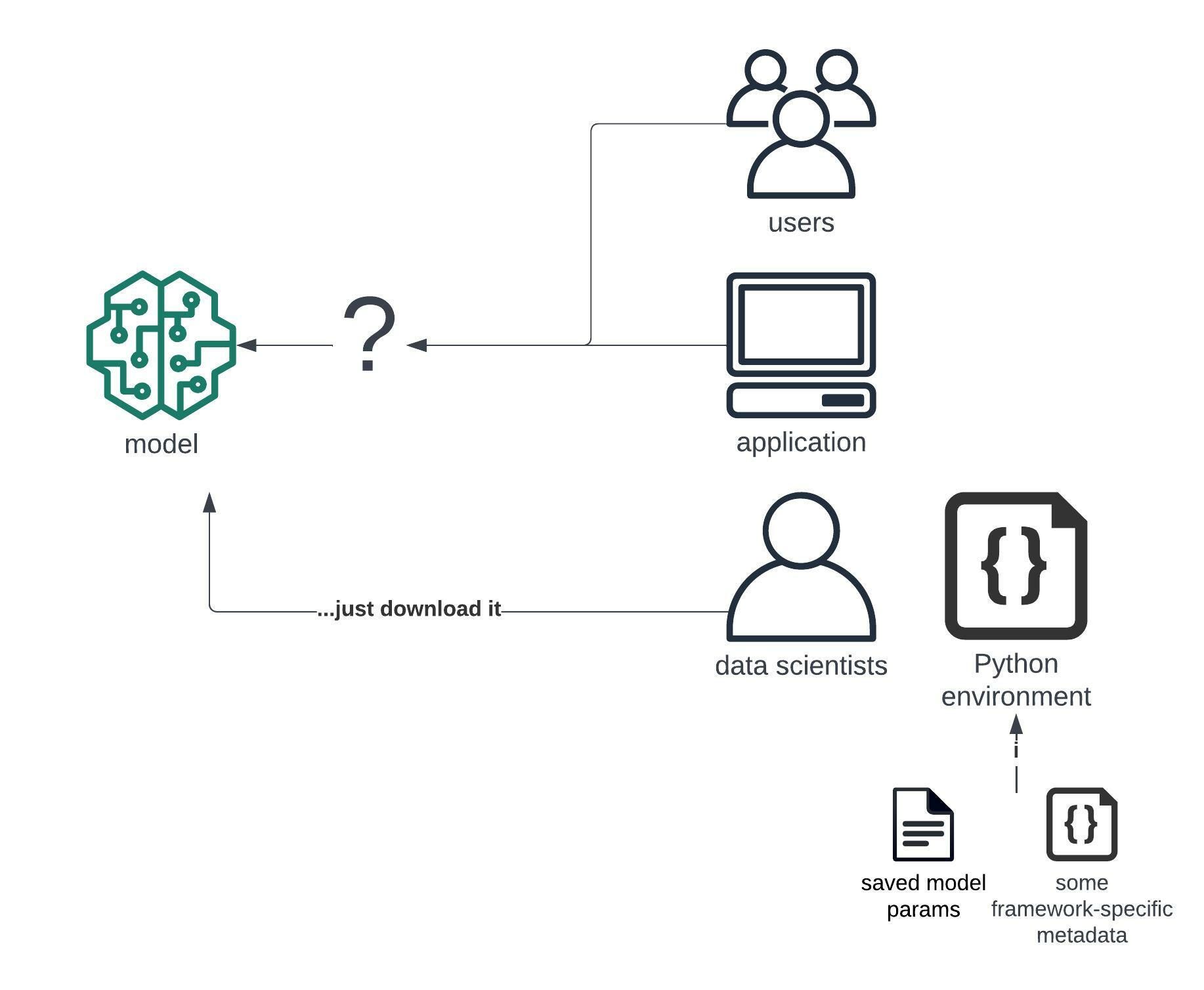
However, for more general audience, especially for letting developers and other applications use the model, this just wouldn't make sense.
That's why model servers and serving layers were introduced!
What is a model server?
If you were to use your model yourself, you’d load it back to memory and then use a method such as predict() to use the model’s knowledge on new data.
What if you wanted to spare others from doing that and just let them use a friendly interface to the model? After all, loading a model to memory and using it requires machine learning knowledge.
Well, the easiest way would be to wrap your model into a tiny application with a friendly interface for others. And in essence, this is basically a model server’s purpose.
A model server (also called an inference server):
loads the model to memory with a correct framework and architecture
utilizes your hardware efficiently while using the model
provides a simple API for others to use the model (HTTP, gRCP)
logs requests, responses and other runtime metrics
For more runtime independence and convenience, the application is often wrapped into a Docker container.

While it doesn’t sound that complex and many teams are tempted to just write your own Flask application to do it, the devil is in the details.
Even the simplest ones still require time to develop and maintain them. Additionally, when your application gets hit by real traffic, some clever computational tricks (such as batching and queueing sequential requests) might be required.
Thus, it usually makes more sense to reuse existing model servers, such as NVIDIA Triton, ones provided Seldon Core or AWS Deep Learning Containers.
What is a serving layer?
Now, the actual deployment part which might actually be the simplest one to understand. We have established what a model is and why a model server is required.
What we lack for now is an environment (well, servers) to run your model servers on.
But from a high level perspective, a model server is merely a Docker container that needs to be run (either on schedule or always). All we need to provide is a regular compute environment with regular servers.
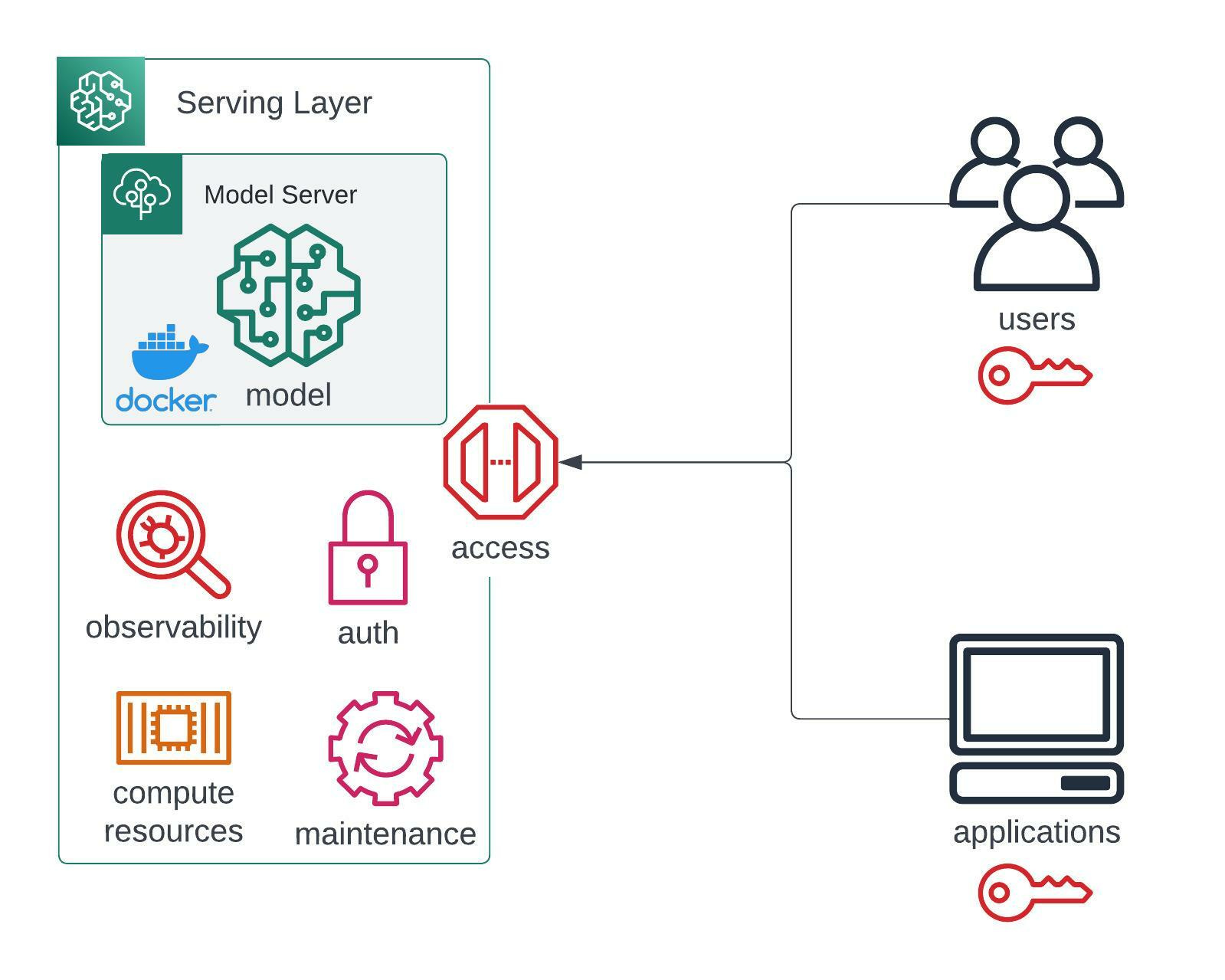
I call it the serving layer - you might also find inference layer used interchangeably. That layer does what the usual compute layers do:
secures your APIs and provides access only to a selected set of users and apps
gives you compute resources and scales itself up and down with the traffic
provides you observability tools to debug errors
lets you easily perform redeployments or A/B tests
This layer sometimes poses buy vs build dilemma. You can:
build it completely on your own (OSS Kubernetes-based stack running on-premises),
use a cloud provider (AWS with SageMaker and other tools)
buy all-in-one SaaS (such as Seldon Cloud)
Building it on your own means maintaining it on your own. On the other hand, using a SaaS black-box often limits the customization abilities. A cloud solution lies somewhere in between.
And so the model deployment picture is complete
You train an algorithm and end up with it’s saved state (a model).
That model is loaded to memory by a tiny application with a friendly interface for users (a model server).
Finally, that model server is run on servers somewhere - on-premises or in the cloud (in a serving layer).