
What's the difference between EC2 vs Lambda, for a web developer?
What I wish someone told me when I worked as Java Developer and listened about AWS Lambda in 2017.

I don’t usually write about regular web development, but with more and more people getting into Lambda ecosystem, I’ll just write what I wish someone told me back in 2017 when I first heard about it.
I don’t plan to force any particular framework to you, nor present pros and cons of every possibility presented below. This is not your usual “YOU MUST USE SERVERLESS” type of article.
What I wish to convey is just the idea behind Lambda execution model and how (and if?) it relates to microservices. You can then go to plethora of other articles that will then try to convince you that their idea is the better one.
Think in events
No matter what kind of app your building, what framework or programming language you’re using and whether you’re in the cloud or not, your application looks like this:
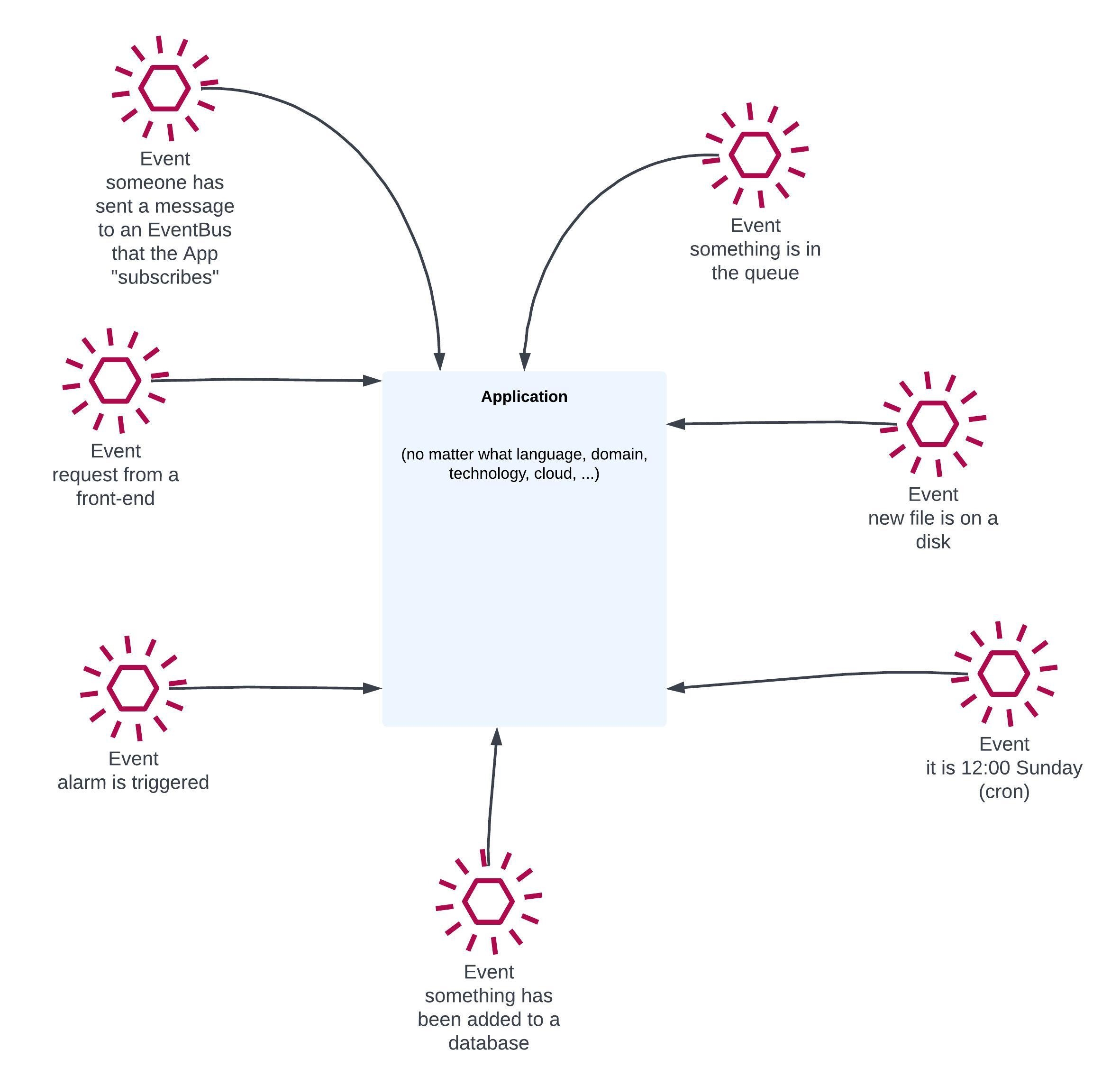
It gets events from somewhere and reacts to them. Yes, in case of web applications, the majority of these are REST/gRCP API calls (“request from a front-end” in this diagram), but if you stop and think about it you can easily find more.
There’s even a term/ideology/idea called Event Driven Architecture. Its main premise is to treat anything happening around your application (i.e. your “business logic”) as a stream of business events. This is more complex though, so for now we can just stick mostly to technical events such as those listed above.
Handling events in servers
Now, your application needs to handle these events. And here comes the major difference between running your app on Lambda versus running your app on a regular server.
In Lambda, it’s up to AWS to ensure there’s compute power required to handle these events by your application. In server-based world, you’re the one to ensure that.
Therefore in server-based apps, event handling process looks as follows:
Sometimes there are multiple VMs with a copy of application. There’s a limit of how many events a VM can handle, depending on its resources (vCPU, RAM, IO, disk), type of events in a given period of time, performance of your code etc. Sometimes you get a lot events to handle during a short period of time. You may, or may not get overwhelmed by that.
You must ensure that at any point there’s enough VMs to handle these events.
The cost of the above is fully dependent on the amount of VMs you’re running each month. AWS just bills you for every second every VM ran in a given month.
Also - there’s absolutely nothing wrong with the above. I’m running such architecture in multiple projects as we speak. You set autoscaling these days and survive even the largest spikes.
Handling events in Lambdas
In Lambda-based apps, the same process looks as follows:
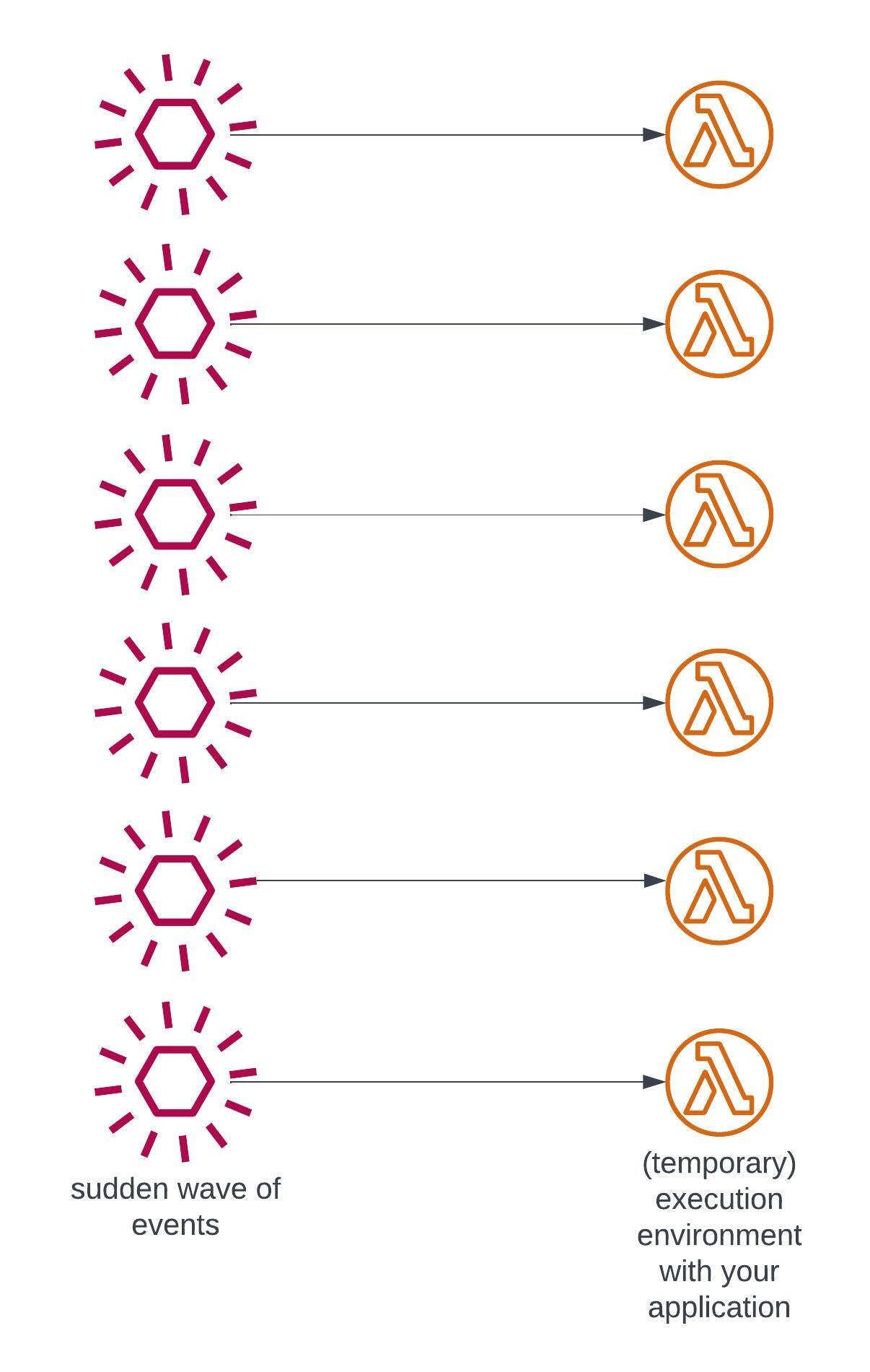
Each event is handled by a temporary, ephemeral, isolated execution environment. You set amount of resources required by an execution environment i.e. how much memory and (implicitly) how much vCPU it needs.
It is as if AWS ran a micro-VM every time an event came to your application.
The cost of the above is billed by two factors:
amount of invocations (1 million invocations costs $x)
every millisecond that a every execution environment executed your code (handled your event)
The second factor is may be less understandable, but if you look at the billing unit of that - GB-second - it may fall into piece. For example, if you handled 1000 events on 1769MB memory execution environment and each took 1s to execute, you’re paying for 1000 x 1769MB-seconds.
…and that’s it. As long as something (more on that in an appendix) sends you these events, your Lambda handles that.
If there are no events to handle, there’s no bill, even if there are executions environments “alive”. If they do not run any code, you’re not paying anything. Plain and simple.
(also, as you can see, there are servers in serverless. It’s just not you who’s managing them)
Where’s the tradeoff, you may ask?
Well, when an event comes to Lambda service and there are no execution environments, or all of them are busy processing existing events, AWS needs to spin up a new one with your code. This takes time (it is called a cold start) and adds an additional latency. There are multiple methods and best practices to lower that, but your p99 and p95 latency metrics will be generally speaking higher than when using servers.
AWS tries to reuse “alive” execution environments but also shuts down unused ones.
There are other tradeoffs too - for large, continuous and predictable traffic Lambda may be just expensive, you lock yourself into AWS, a single event may be executed up to 15 minutes, you don’t control the OS that much, debugging is slightly harder, learning curve is steeper, there are limits of how many events at once you can process, …
Hopefully the above makes it clearer how AWS Lambda mental model is different than what most of us are used to. Instead of running compute power 24/7, scale it up and down, and try to right-size it, you offload that to AWS and let AWS provide compute power for you, automatically, when necessary.
Easy.
Microservices?
Having that in mind, let’s tackle the second topic that is often unnecessarily mixed together with Lambdas, namely microservices.
Here’s a regular, traditional application, often called a monolith:
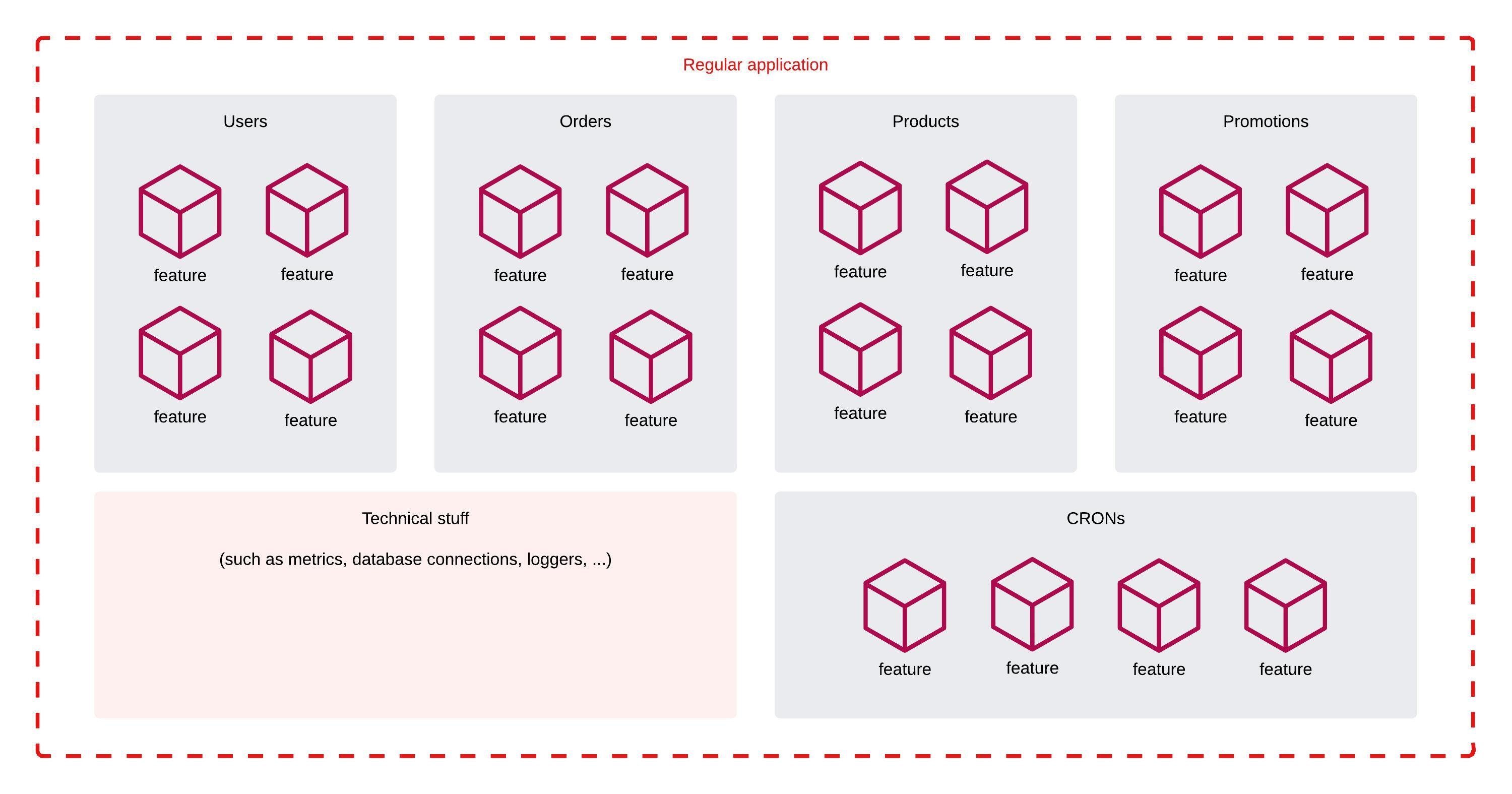
Now, some people for various reasons may decide to split that application into smaller applications, called microservices. This has its own pros and cons, but I won’t tackle them in this article.
Here’s the same application (business-wise) but split into 3 microservices:

For unknown reasons, people think that using Lambda forces you to use microservices (or nanoservices - more on that later). So, let’s tackle the first topic.
No.
Your monolith app oftentimes can be run on AWS Lambda:
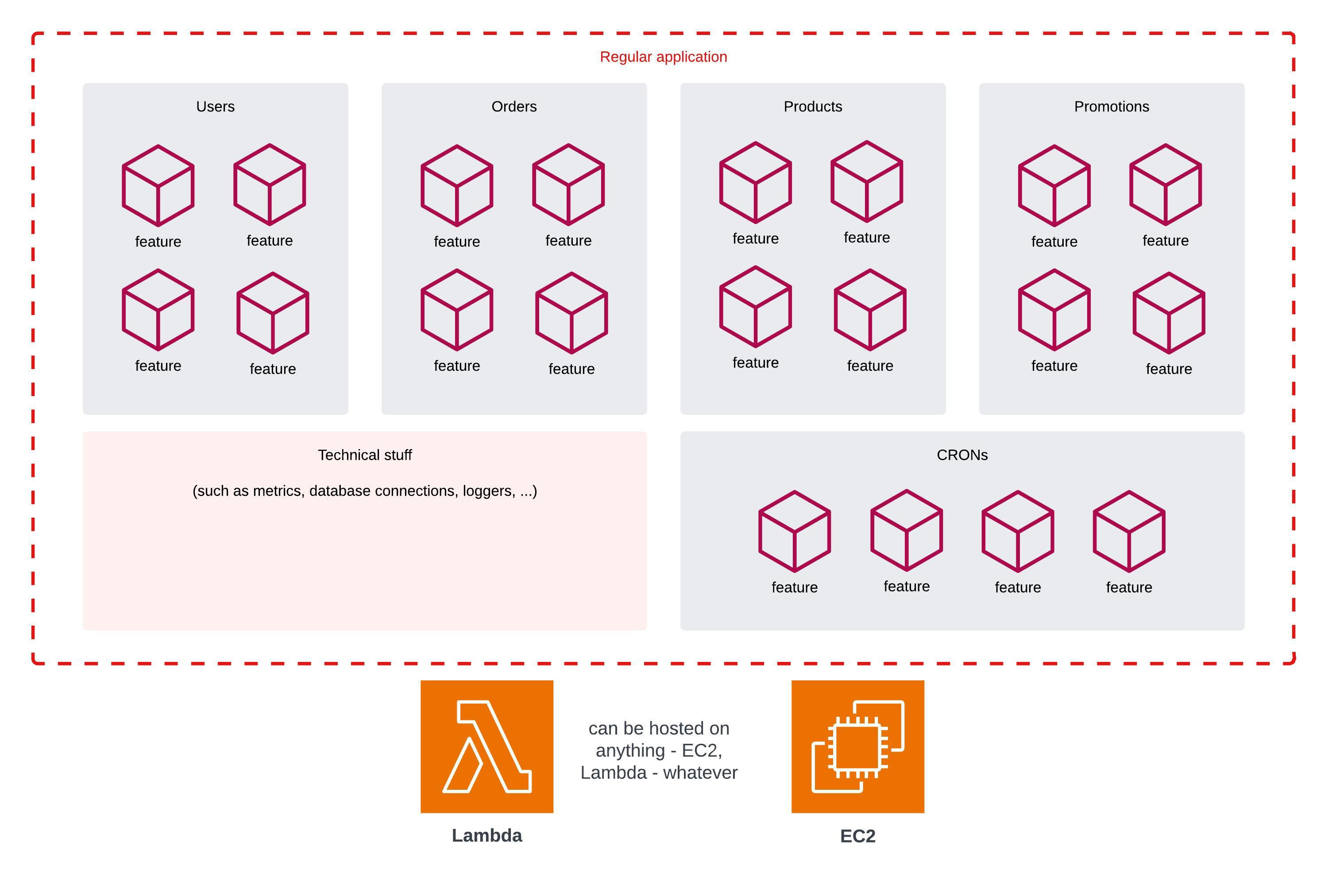
There are adapters and frameworks that allow you to do just that. You can run your existing web frameworks inside AWS Lambda. I call that a fat Lambda. They are especially useful for regular REST APIs.
Yes, some pieces of the app such as database connections, CRONs, metrics or loggers need to be tailored to the fact that the application may not always be alive, frequently “dies” and it also sometimes runs 100s of its “copies” at the same time. There are tricks to achieve that.
But it is certainly possible and I’ve seen that in production do just fine. This might be the easiest entry point for beginners to serverless, especially if your application resembles a traditional CRUD API.
Side note - you can mix EC2s (VMs) and Lambda in the same application. Some parts can be run on the former, some on the latter:

This is frequently a great idea. Event-driven, not-always-running things can be offloaded to Lambda, while busy, stable parts of your system run on EC2. Best of both worlds!
Typical web-app examples that are great-on-Lambda include CRONs (scheduled tasks), processing queues, processing streams or processing files.
Nanoservices?
Let the above sink in before you proceed.
What you already know regarding web development is not useless, you can build projects on Lambda too.
But, yes, there’s another way of building Lambdas. I call it nanoservices. In this pattern, every single feature of your app is an isolated thing in AWS and has its own Lambda to process that. This is depicted below:
At first glance it looked like hell to me back in the days. How do you even manage that? While I could imagine running let’s say 5 or 10 microservices and separate codebases, how do I even manage 100s or 1000s of them?
Turns out …you can do that too and it is quite enjoyable to develop too! There are just frameworks (such as CDK, SST, SAM, Serverless Framework) that support such architecture.
Really.
They often look no different than web frameworks such as Spring, Flask, RoR. In any of the traditional frameworks you create a route and point a method to be executed when that route is triggered. In the Lambda-frameworks, you also create a route and point a method that gets executed when that route . All that these frameworks do for you, is creating all the necessary AWS resources (API Gateway paths, Lambdas, …) automatically.
And yes, you can easily share the codebase of 100s nanoservices just fine, run tests and develop together in a large team.
Should I use fat Lambda or Nanoservices?
Speaking from experience - I’ve seen both executed in many different frameworks. Every time there was a proper tooling and mindset around them, the team was able to rapidly move forward and develop a great system.
Just fire up a SST tutorial to see the nanoservices in action, and then SAM + a single Lambda + Powertools for AWS Lambda to see the fat Lambda pattern. Then decide for yourself.
You can also mix both.
Build your user-facing REST APIs in a Fat Lambda and do everything else (like asynchronous processing of events) via nanoservices. That too works great and is often the best of both worlds.
Appendix - who triggers my Lambdas?
In short - other AWS services do.
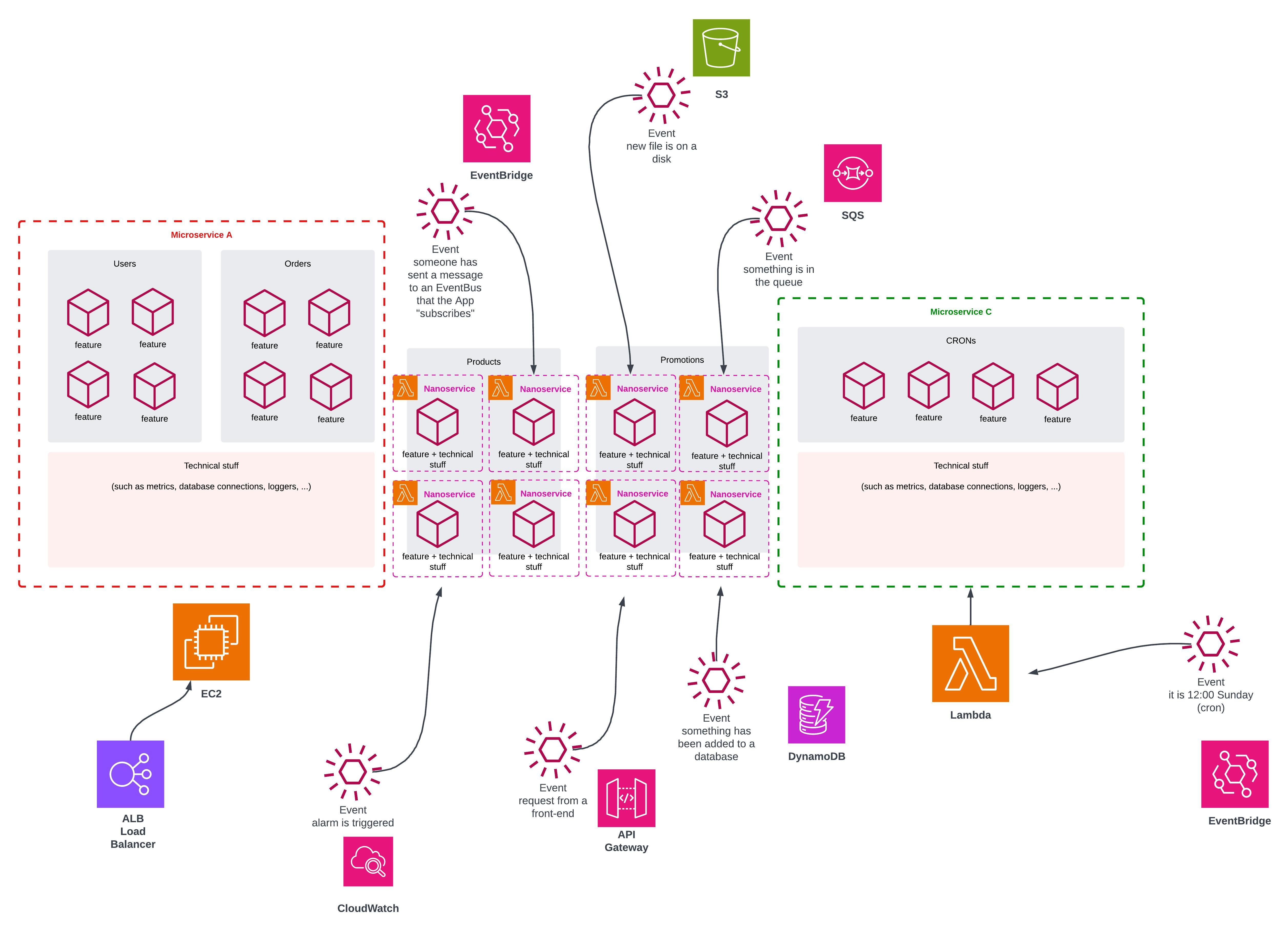
In traditional server-based apps (on the left), requests from users are sent via a load balancer to be handled by your application. The same application is always alive, so it listens to a queue or a stream, ready to process anything that comes up. It also periodically runs some CRON tasks.
In a nanoservices Lambda-world, Lambda is only used to run code. Other services trigger a particular Lambda when it is needed.
when there is a request from a user, API Gateway invokes a selected Lambda
when something has been added to a database, DynamoDB (streams) invokes a selected Lambda to handle that
when an alarm is triggered, CloudWatch invokes a selected Lambda
when a scheduled time has come up, EventBridge invokes a selected Lambda
when a new file on S3 is uploaded, S3 invokes a selected Lambda
when a message is put on a queue, SQS invokes a selected Lambda
…and so on
Therefore your system is built by other AWS components too. And the frameworks that I mentioned fully support writing (and maintaining) all that. This in turns out forces you to think more and more about events, eventual consistency and asynchronous processing, which is not a bad thing.
Neither ChatGPT nor Claude were used to write the above. Thanks for reading!